Para grabar una serie de archivos con cdrecord, directorios, archivos, etc...., lo primero que hay que hacer es convertirlos en imagen iso, y después grabarlos, cerrando el cd, o con multisesión.
En mi caso haríamos:
mkisofs -r -o miimagen.iso 3Cantos/
y después como quiero multisesión haría:
cdrecord -v -multi -data dev=/dev/cdrom miimagen.iso
26 septiembre 2005
20 septiembre 2005
El comando shopt
Mirando en los foros de gentoo encontré una pequeña utilidad de bash (yo sabía que era potente, pero este añadido...).
Si escribimos shopt -s veremos qué variables están activadas y qué variables no.
La que realmente me ha asombrado es shopt -s cdspell; simplemente si nos equivocamos al teclear, nos corrige.
Las otras habrá que investigarlas
Referencia:
14 septiembre 2005
Reinicio con ping remoto
rICMP es un parche del kernel que interactua con la pila TCP/IP y permite reiniciar la máquina remotamente utilizando un paquete Echo de ICMP.
Es muy útil cuando la máquina está medio colgada y no nos permite conectar por ssh, pero si responde al ping. El único caso en el que puede no funcionar es cuando hay "kernel panic".
Hay varias opciones de configuración, así como una contraseña configurable en ascii o hexadecimal.
También hay que tener en cuenta la versión del kernel que se utiliza. Actualmente hay parches para versiones desde el kernel 2.2.19, 2.4.20, 26.12 y por otro lado para kernels entre el 2.4.20-rc1 y el 2.4.21 así como para kernels mayores del 2.6.12.
Referencias:
http://nail.itapac.net/ricmp/
http://jopi.seriousworks.net/item/reiniciar_remotamente_un_servidor_colgado/
20 julio 2005
Han Solo

Pues no estoy hablando de Harrison Ford
Han Solo es mi ordenador del trabajo, es un poco friki, bueno el friki soy yo.
Aquí dejo su foto
Solución a la rotación de logs
He tenido problemas varios días con las rotaciones de logs del apache. Paraban los servidores y me llegaban un montón de alertas al móvil a las 7 de la mañana.
Lo he solucionado simplemente utilizando el programa rotatelogs de apache, de modo que ahora rotamos los logs sin parar el apache, y así si me llega una alarma es de verdad....uuuuuh, qué miedo
Lo he solucionado simplemente utilizando el programa rotatelogs de apache, de modo que ahora rotamos los logs sin parar el apache, y así si me llega una alarma es de verdad....uuuuuh, qué miedo
03 junio 2005
Ubuntu
Al final he instalado el vhcs en Ubuntu, porque misteriosamente el cd de Debian se me quedaba parado al cargar la interrupción 15. ¿Qué le vamos a hacer?.
Ubuntu no me convence demasiado para servidor. No tengo un dominio claro de el sistema de particionado con RAID y con mapper.
Además cuando intenté instalar el vhcs le dio un jamacuco al intentar poner una imagen del kernel.
Al final tuve que quitar el RAID y parece que funciona.
Bueno ahora tengo un problema, y es que pese a que tengo todo como iso-8859-15 en el servidor, el navegador me lo detecta como UTF, con lo cual tengo caracteres raros.
Continuará....
Ubuntu no me convence demasiado para servidor. No tengo un dominio claro de el sistema de particionado con RAID y con mapper.
Además cuando intenté instalar el vhcs le dio un jamacuco al intentar poner una imagen del kernel.
Al final tuve que quitar el RAID y parece que funciona.
Bueno ahora tengo un problema, y es que pese a que tengo todo como iso-8859-15 en el servidor, el navegador me lo detecta como UTF, con lo cual tengo caracteres raros.
Continuará....
01 junio 2005
VHCS
Es un gran programa para la gestión de resellers estilo el cpanel, pero desgraciadamente su instalación es bastante chusca en gentoo, vamos que aún siguiendo algunas instrucciones tengo problemas, si el problema no viene de perl, viene de la ruta de directorios, sino de sabe quién dónde...
Por ello he decidido probar a instalarlo en una Ubuntu. Por qué Ubuntu?, pues porque es debian en un sólo disco, no por otra razón.
A ver cómo evoluciona...
Por ello he decidido probar a instalarlo en una Ubuntu. Por qué Ubuntu?, pues porque es debian en un sólo disco, no por otra razón.
A ver cómo evoluciona...
30 mayo 2005
Forzar Reinicio Linux
Hay veces que por diversas circunstancias los comandos "reboot", "shutdown", "halt", no responden. Esto puede pasar por cualquier motivo, por ejemplo, que tengamos el /sbin en una partición y que se monte de sólo lectura. Con reiniciar el equipo tendríamos el problema resuelto, pero no podemos, porque el sistema nos dice que no reconoce los comandos.
Hay una solución y es lanzando comandos a /proc. El único requisito es tener compilado en el kernel el soporte "magic sysrq key". Esta opción la encontramos en "kernel hacking".
Cuando ya tenemos esta opción compilada en el kernel simplemente tendríamos que ejecutar:
#echo b > /proc/sysrq-trigger
De este modo reiniciaríamos el equipo sin sincronizar discos ni nada, vendría a ser un "reset".
Tendríamos más opciones como parar el equipo, hacer sólo "shutdown" o sincronizar discos.
Todas ellas se pueden encontrar en la documentación del kernel en el archivo
"sysrq.txt"
Hay una solución y es lanzando comandos a /proc. El único requisito es tener compilado en el kernel el soporte "magic sysrq key". Esta opción la encontramos en "kernel hacking".
Cuando ya tenemos esta opción compilada en el kernel simplemente tendríamos que ejecutar:
#echo b > /proc/sysrq-trigger
De este modo reiniciaríamos el equipo sin sincronizar discos ni nada, vendría a ser un "reset".
Tendríamos más opciones como parar el equipo, hacer sólo "shutdown" o sincronizar discos.
Todas ellas se pueden encontrar en la documentación del kernel en el archivo
"sysrq.txt"
23 mayo 2005
Asterisk en Gentoo
Para instalar Asterisk en Gentoo he seguido más o menos las instrucciones de este enlace , realmente he tenido que instalar los sistemas con udev para que no me diera siempre la advertencia de que no tenía udev, y una vez hecho esto seguí el tiki.
Lo primero que hago es desenmascarar asterisk:
echo "net-misc/asterisk ~x86" >> /etc/portage/package.keywords
echo "net-libs/libpri ~x86" >> /etc/portage/package.keywords
echo "net-misc/zaptel ~x86" >> /etc/portage/package.keywords
En el make.conf tengo estos valores:
USE="alsa doc mysql pri zaptel uclib debug vmdbmysql bri speex resperl -X -postgres - gtk -mmx"
Lo primero que hago es desenmascarar asterisk:
echo "net-misc/asterisk ~x86" >> /etc/portage/package.keywords
echo "net-libs/libpri ~x86" >> /etc/portage/package.keywords
echo "net-misc/zaptel ~x86" >> /etc/portage/package.keywords
En el make.conf tengo estos valores:
USE="alsa doc mysql pri zaptel uclib debug vmdbmysql bri speex resperl -X -postgres - gtk -mmx"
20 mayo 2005
VoIP
Ayer asistí a la charla que dio Antonio Pardo en el centro cultural Seco, al ladito de mi casa, y la verdad es que me enteré de bastantes cosas interesantes y me aclaró bastantes dudas, aunque sigo teniendo un millón de ellas.
Por lo menos ya sé qué es lo que me van a poner los de servidores.com en casa, y por qué es tan barato, bueno este último punto todavía no lo tengo muy claro, pero ..... estoy trabajando en ello.
También me aclaró bastante el tema del asterisk, todavía tengo que profundizar bastante, pero ha sido un buen inicio.
Por lo menos ya sé qué es lo que me van a poner los de servidores.com en casa, y por qué es tan barato, bueno este último punto todavía no lo tengo muy claro, pero ..... estoy trabajando en ello.
También me aclaró bastante el tema del asterisk, todavía tengo que profundizar bastante, pero ha sido un buen inicio.
19 mayo 2005
Instalar phpamyadmin Gentoo
Personalmente no soy muy partidiario del uso de estas herramientas, pero bueno por motivos de trabajo lo he tenido que hacer.
La primera vez no me leí foros por internet y como funcionó, no me pregunté más, pero un día dejó de funcionar, así que he vuelto a instalarlo, pero esta vez he encontrado una entrada en un wiki muy valiosa para simplificar los pasos de reinstalación.
La entrada original está aquí, y yo doy una pequeña explicación en castellano:
Lo primero que hacemos es crear la base de datos y los permisos a usuarios necesarios para que funcione phpadmin:
# mysql -u root -p < /usr/share/webapps/phpmyadmin/2.6.2_rc1/sqlscripts/mysql/2.6.1_p2-r1_create.sql Ahora crearemos un usuario y contraseña que serán los que lean los datos de phpmyadmin:
#mysql -u root -p
#mysql> SET PASSWORD FOR 'pma'@'localhost'=PASSWORD('pma_password');
#mysql> quit
Si el servidor web está en una ip y la base de datos en otra, hay que recordar cambiar "localhost" por la ip del servidor correspondiente.
Ahora tenemos que ir a la línea 77 del config.inc.php en el directorio de instalación de phpmyadmin (normalmente en el root del servidor web) y cambiar estos valores:
$cfg['Servers'][$i]['controluser'] = 'root';
$cfg['Servers'][$i]['controlpass'] = '';
Con esto ya funcionaría.
Así que plus,plis,plas, mañana más...
La primera vez no me leí foros por internet y como funcionó, no me pregunté más, pero un día dejó de funcionar, así que he vuelto a instalarlo, pero esta vez he encontrado una entrada en un wiki muy valiosa para simplificar los pasos de reinstalación.
La entrada original está aquí, y yo doy una pequeña explicación en castellano:
Lo primero que hacemos es crear la base de datos y los permisos a usuarios necesarios para que funcione phpadmin:
# mysql -u root -p < /usr/share/webapps/phpmyadmin/2.6.2_rc1/sqlscripts/mysql/2.6.1_p2-r1_create.sql Ahora crearemos un usuario y contraseña que serán los que lean los datos de phpmyadmin:
#mysql -u root -p
#mysql> SET PASSWORD FOR 'pma'@'localhost'=PASSWORD('pma_password');
#mysql> quit
Si el servidor web está en una ip y la base de datos en otra, hay que recordar cambiar "localhost" por la ip del servidor correspondiente.
Ahora tenemos que ir a la línea 77 del config.inc.php en el directorio de instalación de phpmyadmin (normalmente en el root del servidor web) y cambiar estos valores:
$cfg['Servers'][$i]['controluser'] = 'root';
$cfg['Servers'][$i]['controlpass'] = '';
Con esto ya funcionaría.
Así que plus,plis,plas, mañana más...
18 mayo 2005
Proftpd con mysql y cuotas en Gentoo
Instalacion del proftpd Gentoo Linux.
Lo primero que hice fue reflexionar sobre qué era lo que quería.
Principalmente quería usuarios virtuales, no de sistema, que pudieran subir archivos como el usuario apache y con un
sistema que no necesariamente tuviera que ser compatible con ldap, por lo tedioso (para mi) que es trabajar con
ldap (supongo que cuando se tiene un poco de soltura con ello es igual, pero prefiero mysql).
No me importaba que el sistema utilizara o no base de datos en realidad, aunque finalmente fue así.
También quería que escribiera los datos como el usuario apache, para no tener problemas de permisos, puesto que en
el sistema instalado el usuario que corre apache es "apache", y el grupo "apache".
El software que elegí finalmente fue "proftpd". Es un gran sistema ftp que tiene una sintaxis similar a la de
apache, que soporta usuarios virtuales y tiene varios módulos.
Buscando un poco de información en los foros de Gentoo terminé por combinar información de varios documentos hasta
tener el sistema más o menos parido como lo tengo ahora.
En primer lugar lo que puse en los USE del "make.conf" fue "softquota mysql"; de este modo al instalar el proftpd se
instalaba el soporte mysql y el soporte para cuotas por software. Si quisieramos cuotas por hardware, esto ya es
cometido del kernel y del sistema de archivos. Procedemos:
1.- Instalamos:
# emerge proftpd
2.- Creamos la base de datos donde vamos a tener los usuarios, el directorio que van a utilizar, su
contraseña, las cuotas, etc, etc...
Si no tenemos contraseña de root (de mysql) haríamos mysql < type="MyISAM;" type="MyISAM;" uid="9999;" gid="9999;" bytes_in_used =" bytes_in_used" bytes_out_used =" bytes_out_used">
Lo primero que hice fue reflexionar sobre qué era lo que quería.
Principalmente quería usuarios virtuales, no de sistema, que pudieran subir archivos como el usuario apache y con un
sistema que no necesariamente tuviera que ser compatible con ldap, por lo tedioso (para mi) que es trabajar con
ldap (supongo que cuando se tiene un poco de soltura con ello es igual, pero prefiero mysql).
No me importaba que el sistema utilizara o no base de datos en realidad, aunque finalmente fue así.
También quería que escribiera los datos como el usuario apache, para no tener problemas de permisos, puesto que en
el sistema instalado el usuario que corre apache es "apache", y el grupo "apache".
El software que elegí finalmente fue "proftpd". Es un gran sistema ftp que tiene una sintaxis similar a la de
apache, que soporta usuarios virtuales y tiene varios módulos.
Buscando un poco de información en los foros de Gentoo terminé por combinar información de varios documentos hasta
tener el sistema más o menos parido como lo tengo ahora.
En primer lugar lo que puse en los USE del "make.conf" fue "softquota mysql"; de este modo al instalar el proftpd se
instalaba el soporte mysql y el soporte para cuotas por software. Si quisieramos cuotas por hardware, esto ya es
cometido del kernel y del sistema de archivos. Procedemos:
1.- Instalamos:
# emerge proftpd
2.- Creamos la base de datos donde vamos a tener los usuarios, el directorio que van a utilizar, su
contraseña, las cuotas, etc, etc...
Si no tenemos contraseña de root (de mysql) haríamos mysql < type="MyISAM;" type="MyISAM;" uid="9999;" gid="9999;" bytes_in_used =" bytes_in_used" bytes_out_used =" bytes_out_used">
22 marzo 2005
Instalación Servidor Flytech SuperServer 5013C-MT
Básicamente la instalación es como la que que tengo en la otra anotación . En este sin embargo tuve algunos problemillas.
Cuando me dispuse a comentar la instalación no contaba con algunos problemas logísticos, aunque graves. Después de deshacer el array raid cuando comienzo la instalación, resulta que no me detecta los discos duros.
Intenté que me los detectara de todas las maneras, cambiando parámetros en la bios, cambiando de distribución, estuve buscando documentación, pero nada, no había manera.
El problema venía de la controladora SATA Marvel de la que no tenía módulo en el kernel. Al parecer tienen unos módulos para el kernel 2.4, pero por lo que estuve leyendo, ellos te daban las instrucciones para instalarlo si tienes un disco ide además, es decir, primero instalas de la manera normal, y luego compilas el módulo del kernel para tener acceso a los discos, obviamente se tiene acceso a discos como dispositivo de almacenamiento, sin opción a instalar el sistema completo.
Tras leer bastante encontré que podía acceder a los discos también por medio de la controladora SATA de Intel.
De este modo he conseguido que arranquen los discos, tras perder un día en luchar con el cacharro ;-)
Cuando me dispuse a comentar la instalación no contaba con algunos problemas logísticos, aunque graves. Después de deshacer el array raid cuando comienzo la instalación, resulta que no me detecta los discos duros.
Intenté que me los detectara de todas las maneras, cambiando parámetros en la bios, cambiando de distribución, estuve buscando documentación, pero nada, no había manera.
El problema venía de la controladora SATA Marvel de la que no tenía módulo en el kernel. Al parecer tienen unos módulos para el kernel 2.4, pero por lo que estuve leyendo, ellos te daban las instrucciones para instalarlo si tienes un disco ide además, es decir, primero instalas de la manera normal, y luego compilas el módulo del kernel para tener acceso a los discos, obviamente se tiene acceso a discos como dispositivo de almacenamiento, sin opción a instalar el sistema completo.
Tras leer bastante encontré que podía acceder a los discos también por medio de la controladora SATA de Intel.
De este modo he conseguido que arranquen los discos, tras perder un día en luchar con el cacharro ;-)
Peligros VoIP
He leido en barrapunto que la voz sobre ip es fácilmente interceptable. Eso no es de extrañar, si pensamos que la comunicación precisamente se hace a través de internet. También ssh es fácilmente interceptable, aunque no por ello descifrable. De todos modos es lógico que esto ocurra en VoIP contando con que es una tecnología muy nueva. El enlace completo a la noticia es éste.
16 marzo 2005
Experiencias con Windows 2003 Server
He tenido que instalar un Windows XP 2003 Server, o como se llame. Va a tener una base de datos encriptada....blah, blah, blah...., cualquier sistema con Windows en mi opinión no puede ser seguro partiendo del punto de que es susceptible de tener virus, debido a la arquitectura del sistema operativo. Por supuesto que también la mayoría de los virus se hacen para Windows, pero hay que notar que en windows un usuario normal puede hacer cosas que en otros sistemas no podría hacer ni por asomo, y por ejemplo la instalación de cotroles Active X no era cosa del usuario sino del sistema...., en fin mis impresiones....
Lo primero que me ha hecho gracia es que Windows con sus propias controladoras Adaptec de instalación no me reconocía el RAID ni los discos ni nada, 1-0 a favor de linux que a 32 bits si que los reconocía. Tuve que entrar con el disco de arranque de la controladora, y sorpresa!!!!, para arrancar un minisistema funcional con ventanas arrancan un kernel linux con X-Window...juas juas, si es que al final linux vale para algo. Ahí me sale un menú para generar disco de controlador para WinXP (lo más reciente), lo genero, reinicio el sistema y pulso F6 para indicar al sistema de instalación que tengo un disco de controladores del fabricante.
Cuando me pide que introduzca el disco, otra leve sonrisa, me dice que el sistema tiene un controlador más reciente, o sea que si utilizo el controlador reciente no tengo disco, pero si utilizo el anticuado si que lo tengo; utilizo el antiguo.
Bueno instalo Windows como siempre más o menos, eso si que es un 1-1 para Windows que el sistema de instalación es siempre el mismo (para el que ya lo conoce).
Y ahora empieza el festival, recordemos que estoy instalando un servidor. Me advierte unas 50.000 veces sin exagerar que el driver del disco no está firmado por Microsoft, si le hago caso, me quedo sin instalación. Termina la instalación. Me permite añadir el IIS 6.0 que en esta versión no lo instala por defecto, y sorpresa!!!, después de media hora me doy cuenta que no reconoce los drivers de las tarjetas Giga, con lo cual, tengo que meter más controladores, que tampoco están firmados digitalmente.
Cuando ya tengo todo funcionando, o casi todo, porque tuve que meter drivers de controladores de interrupciones, instalo todas las actualizaciones que hay en windows update, y taraaaaaaaan!!!, el sistema me pide reiniciar, lo cual es cojonudo porque indica que si un servidor windows tiene un uptime muy alto es inseguro respecto al software que tiene, y si tiene un uptime como máximo de dos meses, que están realizando las actualizaciones acumulativas...., no es triste???.
Eso sí, si se lee un poco del librito que viene con el sistema operativo, se pueden ver unas 20 o 30 páginas con novedades, y con lo bueno que es que el sistema incorpora esto, aquello y lo de más allá..., casi todas las novedades de Windows están implementadas en linux desde hace años, y además no hace falta reiniciar cada vez que se hace una actualización de seguridad. Sólo hace falta reiniciar en el caso de recompilación del kernel. Que Windows lo puede manejar cualquiera?, pues bueno, pues vale, que cualquiera maneje los servidores windows, que yo preferiría contratar a profesionales... ;-), si no, nos quedamos sin trabajo.....
Lo primero que me ha hecho gracia es que Windows con sus propias controladoras Adaptec de instalación no me reconocía el RAID ni los discos ni nada, 1-0 a favor de linux que a 32 bits si que los reconocía. Tuve que entrar con el disco de arranque de la controladora, y sorpresa!!!!, para arrancar un minisistema funcional con ventanas arrancan un kernel linux con X-Window...juas juas, si es que al final linux vale para algo. Ahí me sale un menú para generar disco de controlador para WinXP (lo más reciente), lo genero, reinicio el sistema y pulso F6 para indicar al sistema de instalación que tengo un disco de controladores del fabricante.
Cuando me pide que introduzca el disco, otra leve sonrisa, me dice que el sistema tiene un controlador más reciente, o sea que si utilizo el controlador reciente no tengo disco, pero si utilizo el anticuado si que lo tengo; utilizo el antiguo.
Bueno instalo Windows como siempre más o menos, eso si que es un 1-1 para Windows que el sistema de instalación es siempre el mismo (para el que ya lo conoce).
Y ahora empieza el festival, recordemos que estoy instalando un servidor. Me advierte unas 50.000 veces sin exagerar que el driver del disco no está firmado por Microsoft, si le hago caso, me quedo sin instalación. Termina la instalación. Me permite añadir el IIS 6.0 que en esta versión no lo instala por defecto, y sorpresa!!!, después de media hora me doy cuenta que no reconoce los drivers de las tarjetas Giga, con lo cual, tengo que meter más controladores, que tampoco están firmados digitalmente.
Cuando ya tengo todo funcionando, o casi todo, porque tuve que meter drivers de controladores de interrupciones, instalo todas las actualizaciones que hay en windows update, y taraaaaaaaan!!!, el sistema me pide reiniciar, lo cual es cojonudo porque indica que si un servidor windows tiene un uptime muy alto es inseguro respecto al software que tiene, y si tiene un uptime como máximo de dos meses, que están realizando las actualizaciones acumulativas...., no es triste???.
Eso sí, si se lee un poco del librito que viene con el sistema operativo, se pueden ver unas 20 o 30 páginas con novedades, y con lo bueno que es que el sistema incorpora esto, aquello y lo de más allá..., casi todas las novedades de Windows están implementadas en linux desde hace años, y además no hace falta reiniciar cada vez que se hace una actualización de seguridad. Sólo hace falta reiniciar en el caso de recompilación del kernel. Que Windows lo puede manejar cualquiera?, pues bueno, pues vale, que cualquiera maneje los servidores windows, que yo preferiría contratar a profesionales... ;-), si no, nos quedamos sin trabajo.....
10 marzo 2005
Problemas a 64 bits
He sido incapaz de instalar Gentoo con los procesadores Intel Xeon con tecnología EM64T.
Comenzando la instalación con el "live cd" de 32 bits no tenía ningún problema, bueno uno sólo, y era que no me reconocían los 4 GB de RAM y sólo me reconocían 3 y pico.
Comenzando la instalación con el "live cd" de 64 bits es decir el de AMD64, me reconocía los 4 GB de RAM, pero no me reconocía ni dispositivos RAID, ni dispositivos SCSI, con lo cual cuando quería particionar me decía que no tenía disco. Lo intenté cargando varios módulos, y nada de nada.
Supongo que el problema viene de la migración del controlador a 64 bits, estuve hablando con un desarrollador de Gentoo AMD64 un tal "Parker" y me dijo que estaban arreglando problemillas que tenían en "udev" antes de sacar una nueva versión del "live cd". De todos modos estuvo intentándolo conmigo hasta que se dio por vencido, con la puñetera controladora ADAPTEC.
Bueno ahora tengo el sistema con Hyperthreading con 4 procesadores y los 4 GB de RAM (esto después de cambiar los máximos del kernel a 64Gb de RAM).
Escribiré sobre la instalación de servidores otro día.
Comenzando la instalación con el "live cd" de 32 bits no tenía ningún problema, bueno uno sólo, y era que no me reconocían los 4 GB de RAM y sólo me reconocían 3 y pico.
Comenzando la instalación con el "live cd" de 64 bits es decir el de AMD64, me reconocía los 4 GB de RAM, pero no me reconocía ni dispositivos RAID, ni dispositivos SCSI, con lo cual cuando quería particionar me decía que no tenía disco. Lo intenté cargando varios módulos, y nada de nada.
Supongo que el problema viene de la migración del controlador a 64 bits, estuve hablando con un desarrollador de Gentoo AMD64 un tal "Parker" y me dijo que estaban arreglando problemillas que tenían en "udev" antes de sacar una nueva versión del "live cd". De todos modos estuvo intentándolo conmigo hasta que se dio por vencido, con la puñetera controladora ADAPTEC.
Bueno ahora tengo el sistema con Hyperthreading con 4 procesadores y los 4 GB de RAM (esto después de cambiar los máximos del kernel a 64Gb de RAM).
Escribiré sobre la instalación de servidores otro día.
08 marzo 2005
Gentoo con los nuevos Intel Xeon con optimizaciones EM64T
Buscando información sobre compilaciones en plataformas intel de 64 bits sólo encontraba información sobre el AMD64. He encontrado diversos sitios en los que indican que para instalar los nuevos procesadores Xeon hay que hacer la instalación de AMD y que así funciona.
En la página de wiki de Gentoo he encontrado un "Cómo" que nos indica cómo compilar el kernel con las extensiones de 64 bits de Intel.
Las modificaciones al make.conf serían estas:
make.conf settings
En la página de wiki de Gentoo he encontrado un "Cómo" que nos indica cómo compilar el kernel con las extensiones de 64 bits de Intel.
Las modificaciones al make.conf serían estas:
make.conf settings
CFLAGS="-O2 -march=nocona -pipe"
CHOST="x86_64-pc-linux-gnu"
CXXFLAGS="${CFLAGS}"
USE="nptl multilib apache2" # This was used for a server running apache
En el kernel habría que seleccionar estos valores:
Kernel Options
Setting the correct Processor Family:
( ) AMD-Opteron/Athlon64
(X) Intel x86-64
( ) Generic-x86-64
04 marzo 2005
Detectando Fallos en array por Software
La información presentada está recogida del Software Raid HOWTO
Personalities : [raid1]
Para simular un fallo por software haríamos:
raidsetfaulty /dev/md1 /dev/sdc2
y eso hace el disco /dev/sdc2 falle en el array /dev/md1. El equivalente a esto en mdadm es
mdadm --manage --set-faulty /dev/md1 /dev/sdc2
Ahora veríamos cómo se empiezan a generar varios fallos en el los logs.
Si hay discos libres pertenecientes al RAID podríamos ver cómo comienza la reconstrucción con dos comandos, o bien lsraid de las raidtools, o bien el mdadm:
mdadm --monitor --mail=root@localhost --delay=1800 /dev/md2
Con este comando estamos diciendo a mdadm que monitorize el dispositivo /dev/md2 cada 1800 segundosy además que envíe el resultado a root@localhost.
nohup mdadm --monitor --scan --daemonise --mail=root@localhost /dev/md0 /dev/md1 &
Hacemos que se demonice la monitorización, que por defecto no está demonizada
- Consultando el estado de los arrays.
Personalities : [raid1]
read_ahead 1024 sectors
md5 : active raid1 sdb5[1] sda5[0]
4200896 blocks [2/2] [UU]
Tenemos que buscar los números que están entre corchetes [#/#]. Estos números nos van a indicar [número de discos en el array / número de
discos activos].
El número de que aparece después de cada dispositivo simplemente indica su posición en el Array.
Si hay un disco roto, después del número de posición aparecerá una F.
Los comandos para ver el estado de los arrays serían:
mdadm --detail /dev/mdx
lsraid -a /dev/mdx
Donde la x indica el número de dispositivo.
- Simulando un fallo en disco
Para simular un fallo por software haríamos:
raidsetfaulty /dev/md1 /dev/sdc2
y eso hace el disco /dev/sdc2 falle en el array /dev/md1. El equivalente a esto en mdadm es
mdadm --manage --set-faulty /dev/md1 /dev/sdc2
Ahora veríamos cómo se empiezan a generar varios fallos en el los logs.
Si hay discos libres pertenecientes al RAID podríamos ver cómo comienza la reconstrucción con dos comandos, o bien lsraid de las raidtools, o bien el mdadm:
lsraid -a /dev/md1
mdadm --detail /dev/md1
- Simulación de Corrupción de datos
- Monitorización de Sistemas RAID
mdadm --monitor --mail=root@localhost --delay=1800 /dev/md2
Con este comando estamos diciendo a mdadm que monitorize el dispositivo /dev/md2 cada 1800 segundosy además que envíe el resultado a root@localhost.
nohup mdadm --monitor --scan --daemonise --mail=root@localhost /dev/md0 /dev/md1 &
Hacemos que se demonice la monitorización, que por defecto no está demonizada
03 marzo 2005
Instalación Servidor Flytech SuperServer 5013C-T
Operativa de instalación de máquinas Flytech con Serial ATA y RAID por Software.
- El servidor a instalar es un SuperServer 5013C-T
- El sistema elegido para instalar es Gentoo Linux, dada la velocidad de estos servidores hemos elegido la instalación mínima para comenzar desde el stage-1.
Que los discos sean SATA no supone ningún problema ya que el sistema operativo lo soporta bien, el problema viene cuando queremos aprovechar el soporte RAID que tiene el equipo. Aunque nos dicen que es una controladora RAID, realmente es un RAID por software. Además no es accesible desde Linux nativamente sino que deberíamos cargar unos módulos en el kernel, que lo único que hacen es darnos soporte a datos. En muchos documentos se encuentra que la gente ha instalado en la misma máquina Windows y Linux, con lo cual, crean el RAID desde Windows y simplemente acceden a esos datos desde Linux.
En nuestro caso nostros queremos el sistema en un RAID 1, y como no podemos con los medios que nos trae el servidor lo haremos mediante una instalación de RAID por software.
Los pasos realizados son los siguientes:
/boot -> 250 Mb
/swap -> 4096 Mb
/ -> 4096 Mb
/resto -> resto
Lo que vamos a hacer es crear los volúmenes raid para estos espacios, luego ya pondremos las particiones que faltan.
Una vez creados los sistemas de ficheros de los dos discos tenemos que cambiar el tipo de partición de todos por "fd" que es "Linux array" (Ver foto).
mknod /dev/md2 b 9 2
mknod /dev/md3 b 9 3
mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1
mdadm --create --verbose /dev/md1 --level=1 --raid-devices=2 /dev/sda2 /dev/sdb2
mdadm --create --verbose /dev/md2 --level=2 --raid-devices=2 /dev/sda3 /dev/sdb3
mdadm --create --verbose /dev/md3 --level=3 --raid-devices=2 /dev/sda4 /dev/sdb4
mdadm es una herramienta para manejar las particiones por software RAID. "Level" le indica el tipo de RAID que queremos hacer y "raid-devices" los dispositivos que forman este array, lógicamente.
Ahora hay que esperar a que termine de hacer la inicialización de los arrays.
Los de cuatro megas son rápidos, pero para los otros hay que tener un poco de paciencia.
Una vez finalizado el proceso editamos /etc/mdadm.conf y ponemos dentro:
DEVICE /dev/sda*
DEVICE /dev/sdb*
ARRAY /dev/md0 devices=/dev/sda1,/dev/sdb1
ARRAY /dev/md1 devices=/dev/sda2,/dev/sdb2
ARRAY /dev/md2 devices=/dev/sda3,/dev/sdb3
ARRAY /dev/md3 devices=/dev/sda4,/dev/sdb4
swapon /dev/md1
modprobe dm-mod
mkdir -p /etc/lvm
echo 'devices { filter=["r/cdrom/" }' > /etc/lvm/lvm.conf
Está bien que no encuentre nada, si no te ha salido a la primera y estás en el segundo intento, también
es lógico que te encuentre el volumen ya creado.
pvcreate /dev/md3
vgcreate vg /dev/md3
Ignoramos los errores "/etc/lvm/backup: fsync failed: Invalid argument" por ahora
lvcreate -L5G -nhome vg
lvcreate -L5G -nopt vg
lvcreate -L10G -nvar vg
lvcreate -L2G -ntmp vg
mkereiserfs /dev/vg/home
mkereiserfs /dev/vg/opt
mkereiserfs /dev/vg/var
mkereiserfs /dev/vg/tmp
mkdir /mnt/gentoo/boot
mkdir /mnt/gentoo/home
mkdir /mnt/gentoo/usr
mkdir /mnt/gentoo/opt
mkdir /mnt/gentoo/var
mkdir /mnt/gentoo/tmp
mount /dev/md0 /mnt/gentoo/boot
mount /dev/vg/usr /mnt/gentoo/usr
mount /dev/vg/home /mnt/gentoo/home
mount /dev/vg/opt /mnt/gentoo/opt
mount /dev/vg/var /mng/gentoo/var
mount /dev/vg/tmp /mnt/gentoo/tmp
Despues de todas historias debemos tener en cuenta varias cosas.
Debemos compilar el soporte para raid 1 en el kernel
Debemos compilar LVM2 como módulo (yo lo he hecho monolítico)
Instalar algunas herramientas
emerge raidtools
emerge mdadm
emerge lvm2
emerge reiserfsprogs
- El servidor a instalar es un SuperServer 5013C-T
- El sistema elegido para instalar es Gentoo Linux, dada la velocidad de estos servidores hemos elegido la instalación mínima para comenzar desde el stage-1.
Que los discos sean SATA no supone ningún problema ya que el sistema operativo lo soporta bien, el problema viene cuando queremos aprovechar el soporte RAID que tiene el equipo. Aunque nos dicen que es una controladora RAID, realmente es un RAID por software. Además no es accesible desde Linux nativamente sino que deberíamos cargar unos módulos en el kernel, que lo único que hacen es darnos soporte a datos. En muchos documentos se encuentra que la gente ha instalado en la misma máquina Windows y Linux, con lo cual, crean el RAID desde Windows y simplemente acceden a esos datos desde Linux.
En nuestro caso nostros queremos el sistema en un RAID 1, y como no podemos con los medios que nos trae el servidor lo haremos mediante una instalación de RAID por software.
Los pasos realizados son los siguientes:
- Entramos en la bios RAID del sistema. Después de ver los textos de la bios normal, vemos unos mensaje de los volúmenes RAID del sistema. Pulsamos [Ctrl-I] con lo cual entramos en las utilidades RAID del Servidor. Aquí borramos el volumen RAID eligiendo la opción 3 (En caso de que tenga alguno activado).
- Reiniciamos la máquina y entramos en la bios normal. Aquí buscamos las opciones avanzadas de Chipset para cambiar RAID por IDE. En el modo SATA tenemos puesto "Enhanced", que por lo visto es válido para PATA y SATA. Si no fuera bien podría probar "Pure SATA".
- Por fin iniciamos con el CD minimal de Gentoo.
- Configuramos la red con #net-setup eth0. Añadimos un servidor de nombres con #echo "nameserver 80.58.0.33" > /etc/resolv.conf. Probamos el ping y vemos que va la red. Si no fuera tendríamos que estar mirando los puertos o si hay algún problema de red, ya que lo necesitamos.
- Tenemos que particionar. Como los discos son SATA el sistema de instalación y el kernel 2.6 hace que se nombren como si fueran scsi, con lo cual vamos a tener /dev/sda y /dev/sdb.
/boot -> 250 Mb
/swap -> 4096 Mb
/ -> 4096 Mb
/resto -> resto
Lo que vamos a hacer es crear los volúmenes raid para estos espacios, luego ya pondremos las particiones que faltan.
Una vez creados los sistemas de ficheros de los dos discos tenemos que cambiar el tipo de partición de todos por "fd" que es "Linux array" (Ver foto).
- Creamos los dispositivos RAID así: mknod /dev/md0 b 9 0
mknod /dev/md2 b 9 2
mknod /dev/md3 b 9 3
- Creamos los array raid donde vamos a tener las particiones:
mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1
mdadm --create --verbose /dev/md1 --level=1 --raid-devices=2 /dev/sda2 /dev/sdb2
mdadm --create --verbose /dev/md2 --level=2 --raid-devices=2 /dev/sda3 /dev/sdb3
mdadm --create --verbose /dev/md3 --level=3 --raid-devices=2 /dev/sda4 /dev/sdb4
mdadm es una herramienta para manejar las particiones por software RAID. "Level" le indica el tipo de RAID que queremos hacer y "raid-devices" los dispositivos que forman este array, lógicamente.
Ahora hay que esperar a que termine de hacer la inicialización de los arrays.
Los de cuatro megas son rápidos, pero para los otros hay que tener un poco de paciencia.
Una vez finalizado el proceso editamos /etc/mdadm.conf y ponemos dentro:
DEVICE /dev/sda*
DEVICE /dev/sdb*
ARRAY /dev/md0 devices=/dev/sda1,/dev/sdb1
ARRAY /dev/md1 devices=/dev/sda2,/dev/sdb2
ARRAY /dev/md2 devices=/dev/sda3,/dev/sdb3
ARRAY /dev/md3 devices=/dev/sda4,/dev/sdb4
- Creamos el sistema de archivos de la partición boot
- Creamos el swap
swapon /dev/md1
- Cramos el sistema de archivos root con reiserfs
- Lanzamos el módulo LVM2
modprobe dm-mod
- Para evitar escaneado innecesario creamos lvm.conf con un filtro de dispositivos:
mkdir -p /etc/lvm
echo 'devices { filter=["r/cdrom/" }' > /etc/lvm/lvm.conf
- Scaneamos la partición LVM
Está bien que no encuentre nada, si no te ha salido a la primera y estás en el segundo intento, también
es lógico que te encuentre el volumen ya creado.
- Creamos el volumen físico LVM en md3
pvcreate /dev/md3
- Creamos el grupo de volúmenes VG
vgcreate vg /dev/md3
Ignoramos los errores "/etc/lvm/backup: fsync failed: Invalid argument" por ahora
- Creamos los particiones en la partición extendida, luego las podemos ampliar:
lvcreate -L5G -nhome vg
lvcreate -L5G -nopt vg
lvcreate -L10G -nvar vg
lvcreate -L2G -ntmp vg
- Creamos el sistema de archivos en las particiones
mkereiserfs /dev/vg/home
mkereiserfs /dev/vg/opt
mkereiserfs /dev/vg/var
mkereiserfs /dev/vg/tmp
- Creamos los puntos de montaje y montamos el sistema:
mkdir /mnt/gentoo/boot
mkdir /mnt/gentoo/home
mkdir /mnt/gentoo/usr
mkdir /mnt/gentoo/opt
mkdir /mnt/gentoo/var
mkdir /mnt/gentoo/tmp
mount /dev/md0 /mnt/gentoo/boot
mount /dev/vg/usr /mnt/gentoo/usr
mount /dev/vg/home /mnt/gentoo/home
mount /dev/vg/opt /mnt/gentoo/opt
mount /dev/vg/var /mng/gentoo/var
mount /dev/vg/tmp /mnt/gentoo/tmp
- Hacemos un stage 3 como trae el handbook de gentoo teniendo en cuenta que deberíamos copiar nuestra información de mdadm
Despues de todas historias debemos tener en cuenta varias cosas.
Debemos compilar el soporte para raid 1 en el kernel
Debemos compilar LVM2 como módulo (yo lo he hecho monolítico)
Instalar algunas herramientas
emerge raidtools
emerge mdadm
emerge lvm2
emerge reiserfsprogs
- El fstab quedaría así:
/dev/md0 /boot ext3 noauto,noatime 1 1
/dev/md2 / reiserfs noatime 0 0
/dev/md1 none swap sw 0 0
/dev/vg/usr /usr reiserfs noatime 0 0
/dev/vg/var /var reiserfs noatime 0 0
/dev/vg/opt /opt reiserfs noatime 0 0
/dev/vg/tmp /tmp reiserfs noatime 0 0
/dev/vg/home /home reiserfs noatime 0 0
/dev/cdroms/cdrom0 /mnt/cdrom iso9660 noauto,ro 0 0
none /proc proc defaults 0 0
none /dev/shm tmpfs defaults 0 0
También hay que arreglar el /etc/lvm/lvm.conf para que inicie rápido
añadiendo esto:
nano -w /etc/lvm/lvm.conf
#fill it with following
devices {
scan=["/dev/md"]
filter=["a|^/dev/md/3$|","r/.*/"]
}
Para aaaa
dd
- Instalación de Grub.
#setup MBR on /dev/hda
root (hd0,0)
setup (hd0)
#setup MBR on /dev/hdg
device (hd0) /dev/hdg
root (hd0,0)
setup (hd0)
En mi caso la configuración que tengo del grub.conf es ésta:
# For booting GNU/Linux
title GNU/Linux
root (hd0,0)
kernel /vmlinuz root=/dev/md2
#initrd /initrd.img
Práticamente todo el material está sacado del Wiki de Gentoo, pero quería añadir mis
cosillas con discos SATA.
Además está por completar y tengo que mostrar la configuración del kernel.
Servidores
De vuelta de los países bajos me he decidido por Gentoo, en el siguiente post que será un how to explicaré todo.
24 febrero 2005
Servidores en Producción
Voy a poner bastantes servidores en producción, y la verdad no sé qué opción elegir.
Gentoo con firewalls openbsd
Debian con firewalls openbsd
Gentoo con gentoo
Debian con debian.
Tengo que ver documentación por ahí y a ver qué ponemos.
En principio me gusta la idea de Gentoo con OpenBSD, pero bueno habrá que buscar comparativas.
Gentoo con firewalls openbsd
Debian con firewalls openbsd
Gentoo con gentoo
Debian con debian.
Tengo que ver documentación por ahí y a ver qué ponemos.
En principio me gusta la idea de Gentoo con OpenBSD, pero bueno habrá que buscar comparativas.
21 febrero 2005
Cómo saber qué versión de glibc tenemos instalada
Siempre se me olvida la lbrería que me indica qué versión de glibc tengo.
Con ejecutar "/lib/libc.so.6" como usuario sin privilegios nos va a indicar qué versión de glibc tenemos en el sistema.
En mi caso la salida sería así:
jose@trinity jose $ "/lib/libc.so.6"
GNU C Library 20040808 release version 2.3.4, by Roland McGrath et al.
Copyright (C) 2004 Free Software Foundation, Inc.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE.
Compiled by GNU CC version 3.3.4 20040623 (Gentoo Linux 3.3.4-r1, ssp-3.3.2-2, pie-8.7.6).
Compiled on a Linux 2.4.21 system on 2004-10-24.
Available extensions:
GNU libio by Per Bothner
crypt add-on version 2.1 by Michael Glad and others
linuxthreads-0.10 by Xavier Leroy
BIND-8.2.3-T5B
libthread_db work sponsored by Alpha Processor Inc
NIS(YP)/NIS+ NSS modules 0.19 by Thorsten Kukuk
Thread-local storage support included.
For bug reporting instructions, please see:
.
Con ejecutar "/lib/libc.so.6" como usuario sin privilegios nos va a indicar qué versión de glibc tenemos en el sistema.
En mi caso la salida sería así:
jose@trinity jose $ "/lib/libc.so.6"
GNU C Library 20040808 release version 2.3.4, by Roland McGrath et al.
Copyright (C) 2004 Free Software Foundation, Inc.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE.
Compiled by GNU CC version 3.3.4 20040623 (Gentoo Linux 3.3.4-r1, ssp-3.3.2-2, pie-8.7.6).
Compiled on a Linux 2.4.21 system on 2004-10-24.
Available extensions:
GNU libio by Per Bothner
crypt add-on version 2.1 by Michael Glad and others
linuxthreads-0.10 by Xavier Leroy
BIND-8.2.3-T5B
libthread_db work sponsored by Alpha Processor Inc
NIS(YP)/NIS+ NSS modules 0.19 by Thorsten Kukuk
Thread-local storage support included.
For bug reporting instructions, please see:
18 febrero 2005
Más comandos
Ojeando un manual de shell avanzado, he encontrado una lista de comandos muy chula. La mayoría son conocidos, otros no me aparecían en el sistema, hasta que caí en la cuenta de que hay que instalarlos, que no vienen por defecto en bash.
Seguiré con estos repaso de comandos, lo mismo, cuando lo tenga completito, lo hago en una sóla página, pero los siguientes que encontré son un pelín más complicados de comprobar, puesto que son de terminales, con lo cual, hasta que no los pruebe no los publico
- users -> muestra el usuario actual
- groups -> muestra el grupo al que pertenece el usuario actual
- useradd -> para añadir usuarios, como root
- userdel -> para borrar usuarios, como root
- usermod -> para modificar una cuenta de usuario
- groupmod -> para modificar un grupo
- id -> muestra el uid y el gid del usuario
- who -> muestra todos los usuarios logeados en el sistema
- w -> muestra los usuarios logeados en el sistema y sus procesos asociados
- logname -> muestra el nombre de usuario actual, tal y como se encuentra en /var/run/utmp
- su -> para cambiar de usuario
- sudo -> para ejecutar cosas como otro usuarios. Previamente hay que modificar el archivo sudoers
- passwd -> para cambiar de contraseña
- last -> últimos usuarios logeados tal y como aparecen en /var/log/wtmp
- newgrp -> permite cambiar el grupo del usuario sin desconecta
- ac -> teóricamente para mostrar el tiempo conectado de los usuarios, pero yo no lo tengo instalado en el sistema ni posibilidad de instalación.
Seguiré con estos repaso de comandos, lo mismo, cuando lo tenga completito, lo hago en una sóla página, pero los siguientes que encontré son un pelín más complicados de comprobar, puesto que son de terminales, con lo cual, hasta que no los pruebe no los publico
17 febrero 2005
Aplicaciones para gestión de archivos
Hay dos aplicaciones muy interesantes que no se me tienen que pasar para trabajar con archivos.
Una es alien. Se trata de una herramienta para utilizar paquetes construidos para otras distribuciones; no está claro, es que me explico como el cu...., mejor pongo un ejemplo.
Supongamos que estoy utilizando Ubuntu; por supuesto los paquetes que instalaré para no complicarme la vida serán paquetes debian, .deb. Encuentro un paquete de una superaplicación que quiero instalar, pero mediante las fuentes es muy engorroso, y no tengo paquete "deb", sólo un "rpm", qué hacer?.
Lo primero es tener instalado "rpm". Una vez instalado utilizo el programa alien para transformarlo de "rpm" a "deb" con este comando:
Mola a que si, eh??.
Por supuesto tiene mogollón de opciones porque además se puede utilizar con paquetes de solaris, slackware, redhat, deb....
La otra aplicación chula es checkinstall.
Vamos a poner el tópico que pone todo el mundo. ¿Cuántas veces has necesitado un programa y no había ni rpm ni deb y sólo disponías de las fuentes? , instalarlo es fácil, pero a la hora de desinstalar, si no has apuntado todos los archivos que te añade al sistema, o los que te modifica, se hace una
labor tediosa, bueno salvo raras excpciones, que tienen desinstalador en las fuentes.
Bueno pues checkinstall en resumidas cuentas es un programa para instalar programas desde el código fuente, y poder desinstalarlos. En mi portátil no hay problema porque utilizo Gentoo, pero para otros como en la oficina que tengo Ubuntu, o en nuestros servidores que tenemos redhat, pues es muy útil.
Próximamente traduciré un artículo para linuxfocus, cuando lo tenga ya lo postearé aquí.
Una es alien. Se trata de una herramienta para utilizar paquetes construidos para otras distribuciones; no está claro, es que me explico como el cu...., mejor pongo un ejemplo.
Supongamos que estoy utilizando Ubuntu; por supuesto los paquetes que instalaré para no complicarme la vida serán paquetes debian, .deb. Encuentro un paquete de una superaplicación que quiero instalar, pero mediante las fuentes es muy engorroso, y no tengo paquete "deb", sólo un "rpm", qué hacer?.
Lo primero es tener instalado "rpm". Una vez instalado utilizo el programa alien para transformarlo de "rpm" a "deb" con este comando:
/usr/bin/alien --to--deb --keep--versionY voila, me va a aparecer el paquete .deb.
xbill_2.0--14_i386.rpm
Mola a que si, eh??.
Por supuesto tiene mogollón de opciones porque además se puede utilizar con paquetes de solaris, slackware, redhat, deb....
La otra aplicación chula es checkinstall.
Vamos a poner el tópico que pone todo el mundo. ¿Cuántas veces has necesitado un programa y no había ni rpm ni deb y sólo disponías de las fuentes? , instalarlo es fácil, pero a la hora de desinstalar, si no has apuntado todos los archivos que te añade al sistema, o los que te modifica, se hace una
labor tediosa, bueno salvo raras excpciones, que tienen desinstalador en las fuentes.
Bueno pues checkinstall en resumidas cuentas es un programa para instalar programas desde el código fuente, y poder desinstalarlos. En mi portátil no hay problema porque utilizo Gentoo, pero para otros como en la oficina que tengo Ubuntu, o en nuestros servidores que tenemos redhat, pues es muy útil.
Próximamente traduciré un artículo para linuxfocus, cuando lo tenga ya lo postearé aquí.
16 febrero 2005
Megabits
Una definición muy chula que he encontrado en Wikipedia para recordar siempre la diferencia entre Megabits y Megabytes:
Megabit
De Wikipedia, la enciclopedia libre.
El Megabit (Mbit o Mb) es una unidad de medida de información muy utilizada en las transmisiones de datos de forma telemática. Representa un millón de bits (1.000.000) y con frecuencia se le confunde con el Megabyte que equivale a 220 (1 048 576) bytes.
Cuando se expresa una velocidad de, por ejemplo, 2 Mbits/s se quiere decir que en un segundo se transmiten 2 millones de bits, o lo que es lo mismo, 2.000.000 / 8 = 250.000 bytes.
Cuestiones de contraseña
No sé qué paranoia ha entrado en todos los blogs últimamente con el cambio de contraseñas. Hay una cosa de la que soy partícipe. O se deniega el acceso externo, o se cambia la contraseña por defecto, y si no, pues ya dependes de la buena fe del que encuentre que tienes la contraseña por defecto.
Un enlace muy interesante que he encontrado viendo Kriptopolis ha sido éste:
Un enlace muy interesante que he encontrado viendo Kriptopolis ha sido éste:
http://www.cirt.net/
Se trata de una página en la que se recopilan contraseñas por defecto de diversos dispositivos y marcas. Muy útil cuando hay que resetear algún router y no se sabe la contraseña por defecto
Se trata de una página en la que se recopilan contraseñas por defecto de diversos dispositivos y marcas. Muy útil cuando hay que resetear algún router y no se sabe la contraseña por defecto
15 febrero 2005
Un pequeño repaso a los comandos
Simplemente quiero hacer un pequeño listado de comandos que seguramente iré ampliando, porque siempre aparecen comandos que se me olvidan, o que no conocía y que merece la pena conocerlos:
Lo dicho, se irá completando esta lista a medida que surgen comandos, o que los recuerdo, porque según lo estaba haciendo recordaba más :-)
- ls -> lista archivos, funciones bastantes complejas como listados recursivos (mirar manual).
- cat y tac -> concatenadores, tac es el reverso de cat. Pone al revés el archivo entero.
- rev -> pone al revés cada línea, es decir cada línea mantiene su orden en el archivo, pero el texto está al revés.
- cp -> copiar
- mv -> cortar, mover
- rm -> borrar
- rmdir -> borrar directorio
- chmod -> cambiar atributos de un archivo
- chown -> cambiar propietario de un archivo
- chgrp -> cambiar grupo de un archivo
- chattr -> cambiar atributos de un archivo, pero sólo para sistemas de archivo ext2 (o ext3, claro).
- ln -> crea enlaces blandos o duros a a archivos.
- basename -> muestra nombre eliminando cualquier elemento del directorio que lo precede, si se especifica también se elimina el sufijo final.
- find -> búsquedas, ni hablar de su tremenda utilidad
- xargs -> ejecuciones, también muy, muy útil.
- grep -> búsquedas de cadenas en archivos.
- sort -> ordena líneas.
- uniq -> muestra líneas no repetidas.
- expr -> para realizar operaciones matemáticas.
Lo dicho, se irá completando esta lista a medida que surgen comandos, o que los recuerdo, porque según lo estaba haciendo recordaba más :-)
14 febrero 2005
A vueltas con los gráficos
Volviendo a los problemillas con el rrdtool, ya tengo los gráficos principales que quiero controlar, y estos son, red (eth0 y eth1), carga de procesador, y memoria (ram y swap), para hacer honor a la verdad, me falta el número de conexiones, que haré luego en un momento.
Todas estas estadísticas las tengo de los cuatro servidores web. Obviamente tendría que hacer estadísticas totales sumando los valores, y del resto de servidores. La cuestión es que no sé qué más valores extraer, valores que no necesiten de leer ningún log, que simplemente los adquiera mediante snmp.
También tengo que valorar si realizar una aplicación o no, o modificar los archivos existentes, hay que valorarlo, teninedo en cuenta que próximamente voy a tener que monitorizar del orden de 14 máquinas.
Lo estudiaré y estudiaré la posibilidad de realizar la aplicación
Todas estas estadísticas las tengo de los cuatro servidores web. Obviamente tendría que hacer estadísticas totales sumando los valores, y del resto de servidores. La cuestión es que no sé qué más valores extraer, valores que no necesiten de leer ningún log, que simplemente los adquiera mediante snmp.
También tengo que valorar si realizar una aplicación o no, o modificar los archivos existentes, hay que valorarlo, teninedo en cuenta que próximamente voy a tener que monitorizar del orden de 14 máquinas.
Lo estudiaré y estudiaré la posibilidad de realizar la aplicación
Código da Vinci
Llevo escasamente una semana leyendo el Código da Vinci de Dan Brown. Previsiblemente lo voy a terminar hoy a la vuelta del trabajo.
Estoy totalmente enganchado con el contenido del libro, pero más que su contenido filosófico, su estilo de aventuras a lo Indiana Jones. Es bastante sencillo de leer, pero engancha. Pero en los últimos capítulos he leido unas cosas bastante interesantes. Además de las implicaciones del Opus, el Sangreal, bla, bla, bla.... los protagonistas "buenos y malos" me recuerdan a los hackers (en el sentido de investigadores, no de crackers), y el desarrollo último, por lo menos en los últimos capítulos, me recuerda a la defensa de Alan Cox de que todo el código debe ser compartido y accesible por todo el mundo. En definitiva, el fin último del GNU. Lo cual también me da pensar otras cosas. Así como en el libro la persona que defiende todos estos fundamentos utiliza artimañas nada lícitas, ¿son lícitos todos los medios que utiliza el software libre?, bueno el software libre no utiliza medios, la pregunta mejor formulada sería: ¿son lícitos todos los medios que utilizan los defendores del software libre?, o bien, ¿tendría que ser todo un "dejar hacer"?.
Sé que no es una inquietud fundamental para el discurrir de los acontecimientos del software libre, pero bueno, es una duda que a veces me asalta a veces.
Estoy totalmente enganchado con el contenido del libro, pero más que su contenido filosófico, su estilo de aventuras a lo Indiana Jones. Es bastante sencillo de leer, pero engancha. Pero en los últimos capítulos he leido unas cosas bastante interesantes. Además de las implicaciones del Opus, el Sangreal, bla, bla, bla.... los protagonistas "buenos y malos" me recuerdan a los hackers (en el sentido de investigadores, no de crackers), y el desarrollo último, por lo menos en los últimos capítulos, me recuerda a la defensa de Alan Cox de que todo el código debe ser compartido y accesible por todo el mundo. En definitiva, el fin último del GNU. Lo cual también me da pensar otras cosas. Así como en el libro la persona que defiende todos estos fundamentos utiliza artimañas nada lícitas, ¿son lícitos todos los medios que utiliza el software libre?, bueno el software libre no utiliza medios, la pregunta mejor formulada sería: ¿son lícitos todos los medios que utilizan los defendores del software libre?, o bien, ¿tendría que ser todo un "dejar hacer"?.
Sé que no es una inquietud fundamental para el discurrir de los acontecimientos del software libre, pero bueno, es una duda que a veces me asalta a veces.
10 febrero 2005
Cambio de nombre
Pues si, éste me gusta más, porque sí, porque soy un friki, y por cambiar un poco, que soy demasiado soso poniendo nombres.
09 febrero 2005
Autoalbum
Pues nada, que ahora tocaba hacer el autoalbum de las imágenes para ver los consumos. Lo primero que pensé fue en utilizar una clase en python, un autogenerador en php, un no sé cuánto en C. Ayer leyendo el Código Davinci me di cuenta de que con hacerlo en bash iba a tener lo que necesitaba.
Pues me puse manos a la obra, y pum!, he escrito un script muy pequeño, muy pequeño que me hace los enlaces de las imágenes de cada directorio. De momento no hace nada más, pero es que lo primero que tengo que hacer es tener gráficas de las máquinas, y luego ya veremos cómo las hacemos bonitas.
Total que el resultado provisional es este:

lo que de momento es una cagada, porque parece que tiene ram libre, cuando no es así, y además no existe ram negativo :-(
Por cierto el código de mi minialbum es éste:
#!/usr/local/bin/bash
cd /usr/local/www/data-dist/rrd/imagenes/
for i in `ls -R|grep "./"|cut -c 3-|awk -F : '{print $1}'`;do
cd $i
ls *.png
if [ $? -eq 0 ];then
rm -rf index.html
touch index.html
for l in `ls *.png`;do
nombre=`basename $l .png`
echo " $nombre" >> index.html
$nombre" >> index.html
done
fi
cd /usr/local/www/data-dist/rrd/imagenes/
done
Por cierto, el enlace a bash es de freebsd, ya se sabe, úsese #!/bin/bash en linux :-)
Sé que no es un prodigio de la programación, pero cumple su función que es lo que importa :-)
Pues me puse manos a la obra, y pum!, he escrito un script muy pequeño, muy pequeño que me hace los enlaces de las imágenes de cada directorio. De momento no hace nada más, pero es que lo primero que tengo que hacer es tener gráficas de las máquinas, y luego ya veremos cómo las hacemos bonitas.
Total que el resultado provisional es este:
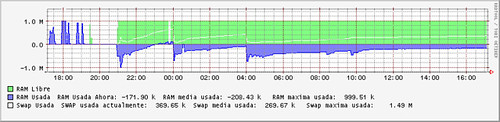
lo que de momento es una cagada, porque parece que tiene ram libre, cuando no es así, y además no existe ram negativo :-(
Por cierto el código de mi minialbum es éste:
#!/usr/local/bin/bash
cd /usr/local/www/data-dist/rrd/imagenes/
for i in `ls -R|grep "./"|cut -c 3-|awk -F : '{print $1}'`;do
cd $i
ls *.png
if [ $? -eq 0 ];then
rm -rf index.html
touch index.html
for l in `ls *.png`;do
nombre=`basename $l .png`
echo "
done
fi
cd /usr/local/www/data-dist/rrd/imagenes/
done
Por cierto, el enlace a bash es de freebsd, ya se sabe, úsese #!/bin/bash en linux :-)
Sé que no es un prodigio de la programación, pero cumple su función que es lo que importa :-)
08 febrero 2005
Creando gráficos con rrdtool
Bueno, ya tengo datos de memoria, y de carga de cpu. He creado el script "gráficos.sh" en el que con funciones y a base de repeticiones deposito los gráficos en un directorio, para luego verlos desde una página web mediante snmp:
#!/bin/bash
AHORA=`date +%s`
HACE_UN_DIA=$(($AHORA-86400))
HACE_DOS_DIAS=$(($AHORA-172800))
HACE_UNA_SEMANA=$(($AHORA-604800))
HACE_UN_MES=$(($AHORA-2419200))
HACE_UN_ANO=$(($AHORA-29030400))
dibuja_grafico()
{
/usr/local/bin/rrdtool graph /usr/local/www/data-dist/rrd/imagenes/servidor1/$1 -s $2 -e $3 -a PNG -b 1024 --width=700 DEF:ramt=/usr/local/www/data-dist/rrd/db/memoria1.rrd:ramtotal:MAX DEF:ramu=/usr/local/www/data-dist/rrd/db/memoria1.rrd:ramusada:MAX DEF:swu=/usr/local/www/data-dist/rrd/db/memoria1.rrd:swapusada:MAX AREA:ramt#80ff80:"RAM Libre\n" AREA:ramu#8080ff:"RAM Usada" GPRINT:ramu:LAST:"RAM Usada Ahora\:%8.2lf %s" GPRINT:ramu:AVERAGE:"RAM media usada\:%8.2lf %s " GPRINT:ramu:MAX:"RAM maxima usada\:%8.2lf %s\n" LINE1:swu#ffffff:"Swap Usada" GPRINT:swu:LAST:"SWAP usada actualmente\:%8.2lf %s" GPRINT:swu:AVERAGE:"Swap media usada\:%8.2lf %s " GPRINT:swu:MAX:"Swap maxima usada\:%8.2lf %s\n" LINE1:ramu#0000ff
}
dibuja_grafico 'memoriaa_ultimo_dia.png' $HACE_UN_DIA $AHORA
dibuja_grafico 'memoriab_dos_dias.png' $HACE_DOS_DIAS $AHORA
dibuja_grafico 'memoriac_ultima_semana.png' $HACE_UNA_SEMANA $AHORA
dibuja_grafico 'memoriad_ultimo_mes.png' $HACE_UN_MES $AHORA
dibuja_grafico 'memoriae_ultimo_ano.png' $HACE_UN_ANO $AHORA
El truquito de las letras detrás de la palabra memoria, es simplemente porque si hago un autoindex (que pretendía hacerlo en python) conseguimos que siga el orden de menos a más tiempo
Hay un pequeño fallo todavía, y son las unidades que salen en la gráfica. No se refiere a bytes, sino a miles por eso es un poco extraño, cuando encuentre la corrección debería ponerla aquí.
#!/bin/bash
AHORA=`date +%s`
HACE_UN_DIA=$(($AHORA-86400))
HACE_DOS_DIAS=$(($AHORA-172800))
HACE_UNA_SEMANA=$(($AHORA-604800))
HACE_UN_MES=$(($AHORA-2419200))
HACE_UN_ANO=$(($AHORA-29030400))
dibuja_grafico()
{
/usr/local/bin/rrdtool graph /usr/local/www/data-dist/rrd/imagenes/servidor1/$1 -s $2 -e $3 -a PNG -b 1024 --width=700 DEF:ramt=/usr/local/www/data-dist/rrd/db/memoria1.rrd:ramtotal:MAX DEF:ramu=/usr/local/www/data-dist/rrd/db/memoria1.rrd:ramusada:MAX DEF:swu=/usr/local/www/data-dist/rrd/db/memoria1.rrd:swapusada:MAX AREA:ramt#80ff80:"RAM Libre\n" AREA:ramu#8080ff:"RAM Usada" GPRINT:ramu:LAST:"RAM Usada Ahora\:%8.2lf %s" GPRINT:ramu:AVERAGE:"RAM media usada\:%8.2lf %s " GPRINT:ramu:MAX:"RAM maxima usada\:%8.2lf %s\n" LINE1:swu#ffffff:"Swap Usada" GPRINT:swu:LAST:"SWAP usada actualmente\:%8.2lf %s" GPRINT:swu:AVERAGE:"Swap media usada\:%8.2lf %s " GPRINT:swu:MAX:"Swap maxima usada\:%8.2lf %s\n" LINE1:ramu#0000ff
}
dibuja_grafico 'memoriaa_ultimo_dia.png' $HACE_UN_DIA $AHORA
dibuja_grafico 'memoriab_dos_dias.png' $HACE_DOS_DIAS $AHORA
dibuja_grafico 'memoriac_ultima_semana.png' $HACE_UNA_SEMANA $AHORA
dibuja_grafico 'memoriad_ultimo_mes.png' $HACE_UN_MES $AHORA
dibuja_grafico 'memoriae_ultimo_ano.png' $HACE_UN_ANO $AHORA
El truquito de las letras detrás de la palabra memoria, es simplemente porque si hago un autoindex (que pretendía hacerlo en python) conseguimos que siga el orden de menos a más tiempo
Hay un pequeño fallo todavía, y son las unidades que salen en la gráfica. No se refiere a bytes, sino a miles por eso es un poco extraño, cuando encuentre la corrección debería ponerla aquí.
Utilizando el rrdtool
Bueno el día no ha empezado demasiado bien, debido a que llegamos a la oficina y no había calefacción, y......, bueno, con la temperatura que hay ahora en Madrid como que no hay quién se quite la chaqueta en la oficina....
Bueno pues hoy he comenzado a instalar...otra vez... el "rrdtool" en un equipo con freebsd. Realmente instalar rrdtool es una tontería, lo que lleva más trabajo es preparar los scripts para la recopilación de datos, pero pensándolo bien, pues puedo hacer hasta una recopilación del estado de la impresora, aunque lo que estoy haciendo es para monitorizar unas máquinas que tenemos en Inglaterra.
Lo mismo que con sed, no quiero olvidarme de lo que estoy haciendo, así que voy a copiar extractos de los archivos que he creado hasta el momento.
Como decía la instalación en freebsd es bastante fácil, parecido a gentoo, simplemente me he ido al "port" de rrdtool y he tecleado "make install", me ha dado un error por culpa de unos parches, pero los he borrado y he vuelto a teclear "make install" y sin problema, se ha compilado e instalado.
De momento sólo estoy recopilando datos de la memoria ram y swap de 4 servidores, y todavía no he creado los scripts de generación de gráficos.
El archivo de creación de las bases de datos tenía algo escrito como esto, pero cuatro veces:
No escribo todos porque es una tontería, todos los mismos datos, pero distinta base de datos. Sé que podía hacer un superscript y automatizar, con bucles, y loops, y patatín y patatán..., bueno he hecho "copiar-pegar" que es una de las grandes novedades de la informática, y he cambiado los nombres de las bases de datos, así que no me ha llevado más de 30 segundos la creación de las bases, además si ha ido bien las de memoria ya no se vuelven a crear.
Hay dos archivos para recopilación de datos:
WEB1=213................ (como que voy a poner la de verdad ;-)
RECOP1="snmpget -v 1 -c public 213............."
TOTALSWAP=" .1.3.6.1.4.1.2021.4.3.0"
SWAPLIBRE=" .1.3.6.1.4.1.2021.4.4.0"
TOTALRAM=" .1.3.6.1.4.1.2021.4.5.0"
RAMLIBRE=" .1.3.6.1.4.1.2021.4.11.0"
En recopmemoria.sh tenemos un script como este (por supuesto con otros datos):
totalswap1=`$RECOP1$TOTALSWAP |awk '{print $4}'`
swaplibre1=`$RECOP1$SWAPLIBRE |awk '{print $4}'`
swapusado1=`expr $totalswap1 - $swaplibre1`
totalram1=`$RECOP1$TOTALRAM |awk '{print $4}'`
ramlibre1=`$RECOP1$RAMLIBRE |awk '{print $4}'`
ramusado1=`expr $totalram1 - $ramlibre1`
/usr/local/bin/rrdtool update /usr/local/www/data-dist/rrd/db/memoria1.rrd \ N:$totalram1:$ramusado1:$totalswap1:$swapusado1
Bueno y luego simplemente añadí una entrada en el cron que lo ejecute cada
5 minutos
*/5 * * * * /home/scripts/recopmemoria.sh >/dev/null 2>&1
Nota: he tenido que modificar al principo del recopmemoria.sh porque sino me daba un error al no encontrar la fuente del archivo de datos, de modo que he escrito:
#!/usr/local/bin/bash
cd /home/scripts
. datos-comunes
Por qué utilizo rrdtool?, pues por lo mismo que utilizo gentoo, por comodidad, sé que podría tener gráficas con mrtg, pero de hecho no tengo la flexibilidad que tengo con rrdtool, ni podría incluir más de dos fuentes de datos en una gráfica....y porque me da la gana, que yo no obligo a nadie a que ponga las gráficas que uso yo :-)
En siguientes entregas iré completando, a ver si puedo hacer un complemento majo para rrdtool.
Bueno pues hoy he comenzado a instalar...otra vez... el "rrdtool" en un equipo con freebsd. Realmente instalar rrdtool es una tontería, lo que lleva más trabajo es preparar los scripts para la recopilación de datos, pero pensándolo bien, pues puedo hacer hasta una recopilación del estado de la impresora, aunque lo que estoy haciendo es para monitorizar unas máquinas que tenemos en Inglaterra.
Lo mismo que con sed, no quiero olvidarme de lo que estoy haciendo, así que voy a copiar extractos de los archivos que he creado hasta el momento.
Como decía la instalación en freebsd es bastante fácil, parecido a gentoo, simplemente me he ido al "port" de rrdtool y he tecleado "make install", me ha dado un error por culpa de unos parches, pero los he borrado y he vuelto a teclear "make install" y sin problema, se ha compilado e instalado.
De momento sólo estoy recopilando datos de la memoria ram y swap de 4 servidores, y todavía no he creado los scripts de generación de gráficos.
El archivo de creación de las bases de datos tenía algo escrito como esto, pero cuatro veces:
/usr/local/bin/rrdtool create /usr/local/www/data-dist/rrd/db/memoria1.rrd \
DS:ramtotal:GAUGE:600:U:U \
DS:ramusada:GAUGE:600:U:U \
DS:swaptotal:GAUGE:600:U:U \
DS:swapusada:GAUGE:600:U:U \
RRA:AVERAGE:0.5:1:600 \
RRA:AVERAGE:0.5:6:700 \
RRA:AVERAGE:0.5:24:775 \
RRA:AVERAGE:0.5:288:797 \
RRA:MAX:0.5:1:600 \
RRA:MAX:0.5:6:700 \
RRA:MAX:0.5:24:775 \
RRA:MAX:0.5:288:797
DS:ramtotal:GAUGE:600:U:U \
DS:ramusada:GAUGE:600:U:U \
DS:swaptotal:GAUGE:600:U:U \
DS:swapusada:GAUGE:600:U:U \
RRA:AVERAGE:0.5:1:600 \
RRA:AVERAGE:0.5:6:700 \
RRA:AVERAGE:0.5:24:775 \
RRA:AVERAGE:0.5:288:797 \
RRA:MAX:0.5:1:600 \
RRA:MAX:0.5:6:700 \
RRA:MAX:0.5:24:775 \
RRA:MAX:0.5:288:797
No escribo todos porque es una tontería, todos los mismos datos, pero distinta base de datos. Sé que podía hacer un superscript y automatizar, con bucles, y loops, y patatín y patatán..., bueno he hecho "copiar-pegar" que es una de las grandes novedades de la informática, y he cambiado los nombres de las bases de datos, así que no me ha llevado más de 30 segundos la creación de las bases, además si ha ido bien las de memoria ya no se vuelven a crear.
Hay dos archivos para recopilación de datos:
- datos-comunes; aquí he puesto los datos que son comunes haga los scripts que haga
- recopmemoria.sh; el porqué del nombre es que lo tecleé mal, pero total no molesta, este es el script que recoge los datos propiamente y los introduce en memoria
WEB1=213................ (como que voy a poner la de verdad ;-)
RECOP1="snmpget -v 1 -c public 213............."
TOTALSWAP=" .1.3.6.1.4.1.2021.4.3.0"
SWAPLIBRE=" .1.3.6.1.4.1.2021.4.4.0"
TOTALRAM=" .1.3.6.1.4.1.2021.4.5.0"
RAMLIBRE=" .1.3.6.1.4.1.2021.4.11.0"
En recopmemoria.sh tenemos un script como este (por supuesto con otros datos):
totalswap1=`$RECOP1$TOTALSWAP |awk '{print $4}'`
swaplibre1=`$RECOP1$SWAPLIBRE |awk '{print $4}'`
swapusado1=`expr $totalswap1 - $swaplibre1`
totalram1=`$RECOP1$TOTALRAM |awk '{print $4}'`
ramlibre1=`$RECOP1$RAMLIBRE |awk '{print $4}'`
ramusado1=`expr $totalram1 - $ramlibre1`
/usr/local/bin/rrdtool update /usr/local/www/data-dist/rrd/db/memoria1.rrd \ N:$totalram1:$ramusado1:$totalswap1:$swapusado1
Bueno y luego simplemente añadí una entrada en el cron que lo ejecute cada
5 minutos
*/5 * * * * /home/scripts/recopmemoria.sh >/dev/null 2>&1
Nota: he tenido que modificar al principo del recopmemoria.sh porque sino me daba un error al no encontrar la fuente del archivo de datos, de modo que he escrito:
#!/usr/local/bin/bash
cd /home/scripts
. datos-comunes
Por qué utilizo rrdtool?, pues por lo mismo que utilizo gentoo, por comodidad, sé que podría tener gráficas con mrtg, pero de hecho no tengo la flexibilidad que tengo con rrdtool, ni podría incluir más de dos fuentes de datos en una gráfica....y porque me da la gana, que yo no obligo a nadie a que ponga las gráficas que uso yo :-)
En siguientes entregas iré completando, a ver si puedo hacer un complemento majo para rrdtool.
Correos con comando "mail"
Una función muy importante de linux muy poco aprovechada es el comando "mail" que sirve para enviar correo. Está muy poco aprovechada por mi, porque casi en exclusiva escribo "mail <>" cuando se pueden poner más cosas si utilizamos las opciones, como por ejemplo:
- -s: ponemos asunto
- -c: copiamos a alguien
- -b: copia oculta
echo "Vamos mañana" | mail -c pepe@dominio.com -b marta@dominio.com -s "fiesta" carlos@dominio.comEl tratamiento de archivos será lo próximo. Tenía que escribir esto para que no se me olvidara, como fuente shelldorado, pero lo de los archivos si que va a ser tomado en total de la página.
En algunas versiones de sistemas operativos no está disponible
el programa mail porque tienen la versión extendida "mailx",
o porque el comando no es "mail" sino "Mail" con mayúscula.
31 enero 2005
El cine español
Ayer fue la entrega de los premios Goya, burda imitación de la entrega de los burdos Oscar, pero a la española.
Tengo que reconocer que me encanta el cine, pero odio fervientemente todo lo que circula a su alrededor, como odio todo el ambiente de podredumbre que hay alrededor de los grandes ejecutivos de grandes empresas, de las fiestas de "mírame bien y no me toques", y en definitiva, de todo lo que significa apariencia e interés.
Pero ayer todos en su discurso hablaban de una cosa con la que estoy muy de acuerdo y no era de la gerra de Irak, menos mal que por una vez dejaron los tópicos antiamericanos. Hablaron del no al top-manta. Yo también estoy de acuerdo.... a medias.
Hay que reconocer que el precio de los DVD es bastante bajo, podría serlo más, pero es asequible para todo el mundo. De hecho grabar un DVD es más caro que comprarlo. Además, conociendo a gente que trabaja en este mundillo, que no me gusta, sé que hay mucha gente que pagar, mucho material que utilizar, mucho riesgo que correr, y más que perder que ganar, a menos que se tengan buenos contactos y se cuele la película con calzador, tenga la calidad que tenga.
Pero hay una cosa con la que no estoy de acuerdo. Se toma el top-manta como el cáncer que perjudica en todos los aspectos al cine. ¿Qué precio tendrían las películas originales si no hubiera top manta?, ¿cuántas bazofias nos colarían si no hubiera top-manta?. ¿Aca so ha bajado el sueldo de los actores?. Con una sola película se pueden comprar una casa, y yo tengo que esperar 35 años a ser dueño de mi casa, y eso en el supuesto de que me den la hipoteca.
Luego caso aparte es la música. Sociedades que consiguen dinero por varios frentes a costa del usuario final, alegando la defensa del autor, y que la cultura tiene un precio. Oiga usted, sinceramente, como está de cara la vida, si la cultura tiene un precio, prefiero ser un inculto, y poder pagar la luz y el agua.
Tengo que reconocer que me encanta el cine, pero odio fervientemente todo lo que circula a su alrededor, como odio todo el ambiente de podredumbre que hay alrededor de los grandes ejecutivos de grandes empresas, de las fiestas de "mírame bien y no me toques", y en definitiva, de todo lo que significa apariencia e interés.
Pero ayer todos en su discurso hablaban de una cosa con la que estoy muy de acuerdo y no era de la gerra de Irak, menos mal que por una vez dejaron los tópicos antiamericanos. Hablaron del no al top-manta. Yo también estoy de acuerdo.... a medias.
Hay que reconocer que el precio de los DVD es bastante bajo, podría serlo más, pero es asequible para todo el mundo. De hecho grabar un DVD es más caro que comprarlo. Además, conociendo a gente que trabaja en este mundillo, que no me gusta, sé que hay mucha gente que pagar, mucho material que utilizar, mucho riesgo que correr, y más que perder que ganar, a menos que se tengan buenos contactos y se cuele la película con calzador, tenga la calidad que tenga.
Pero hay una cosa con la que no estoy de acuerdo. Se toma el top-manta como el cáncer que perjudica en todos los aspectos al cine. ¿Qué precio tendrían las películas originales si no hubiera top manta?, ¿cuántas bazofias nos colarían si no hubiera top-manta?. ¿Aca so ha bajado el sueldo de los actores?. Con una sola película se pueden comprar una casa, y yo tengo que esperar 35 años a ser dueño de mi casa, y eso en el supuesto de que me den la hipoteca.
Luego caso aparte es la música. Sociedades que consiguen dinero por varios frentes a costa del usuario final, alegando la defensa del autor, y que la cultura tiene un precio. Oiga usted, sinceramente, como está de cara la vida, si la cultura tiene un precio, prefiero ser un inculto, y poder pagar la luz y el agua.
28 enero 2005
A vueltas con el Geotarget
Ha sido un día productivo, en su primera parte.
Hemos configurado el geoip de Maxmind en las máquinas de Verio. Bueno, realmente las había configurado hace un par de días, y hoy estaba contrariado porque no estaba funcionando, y salía la página por defecto en inglés.
Finalmente hemos encontrado que "alguien" me había comentado las entradas del módulo geoip con lo cual no estaba funcionando. Lo descomentamos y funciona perfectamente, cómo no......(aplausos.... ;-).
Ayer a última hora además instalé MySQL en dos servers. Instalé la versión 4.1.9 que permite subselects y que cumple con los estándares ACID, aunque no creo que vayamos a utilizar estas características.
Ahora tengo que generar unas estadísticas que todavía las hago manualmente, y finalmente hay un reto bonito que es programar un módulo de apache.
Hemos configurado el geoip de Maxmind en las máquinas de Verio. Bueno, realmente las había configurado hace un par de días, y hoy estaba contrariado porque no estaba funcionando, y salía la página por defecto en inglés.
Finalmente hemos encontrado que "alguien" me había comentado las entradas del módulo geoip con lo cual no estaba funcionando. Lo descomentamos y funciona perfectamente, cómo no......(aplausos.... ;-).
Ayer a última hora además instalé MySQL en dos servers. Instalé la versión 4.1.9 que permite subselects y que cumple con los estándares ACID, aunque no creo que vayamos a utilizar estas características.
Ahora tengo que generar unas estadísticas que todavía las hago manualmente, y finalmente hay un reto bonito que es programar un módulo de apache.
27 enero 2005
Empezando
Pues no sé qué ha pasado, pero parece que soy un poco muñones con esto de los blogs. Lo abrí ayer, y hoy ya me he cargado la página de entrada.
Esperemos que poco a poco me vaya enterando de la vaina y vaya escribiendo más utilidades.
Esperemos que poco a poco me vaya enterando de la vaina y vaya escribiendo más utilidades.
Útiles para encontrar y borrar...y algo de "sed"
Cuando ejecutamos un comando de bash y nos dice que la lista de argumentos es demasiado larga, por ejemplo, cuando queremos borrar los miles de mensajes de correo que podemos tener en nuestro directorio de cuarentena (-bash: /bin/rm: La lista de argumentos es demasiado larga), podemos utilizar el comando find, para hacerlo de varias maneras:
Otra utilidad, a partir de lo anterior es buscar una cadena recursivamente dentro de un cualquier fichero en el directorio actual:
Utilizo "sed" para sustituir cadenas dentro de archivos, pero también está la utilidad de convertir archivos de Unix a DOS y viceversa. Recordemos que el final de línea de los archivos dos (vamos, quien dice dos, dice windows) es \r\n, y el final de línea en los archivos unix es \n, por eso aparecen los caracteres raros a veces cuando se abre con "vi" un archivo escrito en windows. Como nunca me acuerdo de las expresiones regulares concretas para hacer esto ahí van:
Ya el último caso es convertir archivos unix a windows desde un entorno windows. Por supuesto primero hay que tener instalado el sed para windows:
Estos casos de "sed" están sacados de la página en sourceforge.
- find . -name "cadenaquesea" -exec rm {} \;
- find . -name "cadenaquesea" -exec rm -i {} \; (El parámetro "-i" simplemente es para indicarle a rm que haga un borrado interactivo, por si no estamos seguros de que funcione bien el temita).
- find . -name "cadenaquesea" | xargs rm; (La gente no estaba muy contenta con esta manera de hacer el borrado, porque decía que "xargs" al final perdía resultados aunque no diera el error de que la lista era larga, por eso no les gustaba.
Otra utilidad, a partir de lo anterior es buscar una cadena recursivamente dentro de un cualquier fichero en el directorio actual:
- find . -type f -exec grep "
" {} \; -print
Utilizo "sed" para sustituir cadenas dentro de archivos, pero también está la utilidad de convertir archivos de Unix a DOS y viceversa. Recordemos que el final de línea de los archivos dos (vamos, quien dice dos, dice windows) es \r\n, y el final de línea en los archivos unix es \n, por eso aparecen los caracteres raros a veces cuando se abre con "vi" un archivo escrito en windows. Como nunca me acuerdo de las expresiones regulares concretas para hacer esto ahí van:
- sed 's/.$//' #asume que todas las líneas terinan con retorno de carro y salto de línea, con lo que se carga todo lo del final.
- sed 's/^M$//' #en bash y tcsh, y que se presione Ctrl-V y luego Ctrl-M, no me pispo a qué se refiere, y además, nunca me ha funcionado
- sed 's/\x0D$//' # gsed 3.02.80, pero el script de arriba es más fácil, la verdad yo siempre he utilizado el primero
- sed "s/$/`echo -e \\\r`/" #bajo ksh
- sed 's/$'"/`echo \\\r`/" #bajo bash
- sed "s/$/`echo \\\r`/" #bajo zsh
- sed 's/$/\r/' #gsed 3.02.80
Ya el último caso es convertir archivos unix a windows desde un entorno windows. Por supuesto primero hay que tener instalado el sed para windows:
- sed "s/$//"
- sed -n p
Estos casos de "sed" están sacados de la página en sourceforge.
Suscribirse a:
Entradas (Atom)